Data · Infrastructure · Analytics
Ravi
Rajpurohit
I build the pipelines, platforms, and analytics layers that turn raw data into decisions.
2B+
events/month processed
10M+
users served
5M+
records/day through current pipelines
About
Building data systems
that actually get used.
I've spent the last several years building pipelines that process billions of events per month, cloud data platforms that cut executive reporting from days to under an hour, and data visualizations that make complex datasets worth looking at.
Before my MS in Computer Science at UT Arlington, I built the data backbone for a wearable health platform at KaHa Technologies — Kafka ingestion, real-time telemetry, 10M+ users. I'm most interested in the full picture: from how data gets ingested to whether the person reading the dashboard actually trusts what it shows.
⚡ Outside of work: 🏸 racket sports, 🎸 music, 🧑🍳 cooking — and yes, I once worked as a chef for my university.

Capabilities
What I Build
End-to-End Data Pipelines
Kafka ingestion at 2B+ events/month, Python and PySpark transformations, dbt modeling, dimensional schemas — the whole chain from raw source to analytics-ready table.
Cloud Data Platforms
AWS (Glue, Athena, Spark, S3), Snowflake, Databricks, DuckDB. I care about what each tool actually costs and whether engineers will be able to maintain it six months later.
Analytics & BI
Executive dashboards, D3.js data stories, self-serve reporting. I think about who is going to open this dashboard at 8am and what they actually need to see — not just what the data model can technically produce.
ML-Enabling Infrastructure
Feature pipelines and data layers for real-time ML inference — health wearable telemetry at 10M+ user scale, high-frequency biosensor research at 200Hz. The ML model is only as good as the data it gets.
Experience
Where I've Worked
Data Infrastructure Engineer
State of Michigan — Ottawa Area ISD
- Built an AWS data lake consolidating 15+ siloed data sources — cut executive report generation from 3 days to under 1 hour.
- Designed ELT pipelines in Python and PySpark processing 5M+ daily records; provisioned the full stack as a serverless, event-driven architecture using AWS CloudFormation.
- Orchestrated pipeline runs with AWS Step Functions with full audit logging and automated alerting.
- Built semantic-layer dashboards in Tableau, Power BI, and QuickSight — translating dimensional models into business-readable language accessible to non-technical stakeholders.
- Accelerated team productivity by 20% by integrating AI coding assistants into documentation and development workflows.
Software Data Engineer — Wearables & MLOps
KaHa Technologies
- Built a real-time telemetry pipeline on Apache Kafka processing 2B+ monthly events from 10M+ wearbles users with end-to-end lag under 5 seconds.
- Designed a multi-store data layer (DynamoDB, S3, Redshift) matched to each access pattern — from low-latency device reads to batch ML training and warehouse analytics.
- Built observability and data quality monitoring pipelines with Prometheus, catching bad data upstream of data science workflows and accelerating model iteration speed by 25%.
- Established A/B testing infrastructure and self-serve analytics capabilities that empowered product teams to independently evaluate experiments, contributing to 20x company growth over 2 years.
- Built a Firebase + BigQuery app performance pipeline tracking connection and sync behavior across Android and iOS devices, with automated daily reports to QA.
Data Engineer Intern — Cloud & APIs
Nutanix
- Built a GoLang REST API for internal performance analytics, deployed on Kubernetes via Jenkins CI/CD and integrated into IAM via JWT to eliminate re-authentication friction.
- Served as the bridge between engineering and analytics to define source-to-target data contracts; delivered role-based dashboards for Support and Sales from 500GB+ of daily product telemetry.
- Awarded 2nd place in the company-wide hackathon for prototyping a product recommendation module powered by customer usage signals.
Data Engineer — Research Applications
University of Texas at Arlington
- Built a signal processing and feature extraction pipeline for wearable PPG sensor data at 200Hz, enabling ML inference for health research.
- Orchestrated ETL workflows with Apache Airflow, reducing processing latency by 35%.
- Implemented automated data quality tests with dbt and daily job execution monitoring, ensuring signal integrity before data reached ML feature extraction.
Education
MS Computer Science
University of Texas at Arlington
Also while there
Work
Featured Projects
Projects with a Case Study include architecture diagrams, data models, and the key engineering decisions behind them.
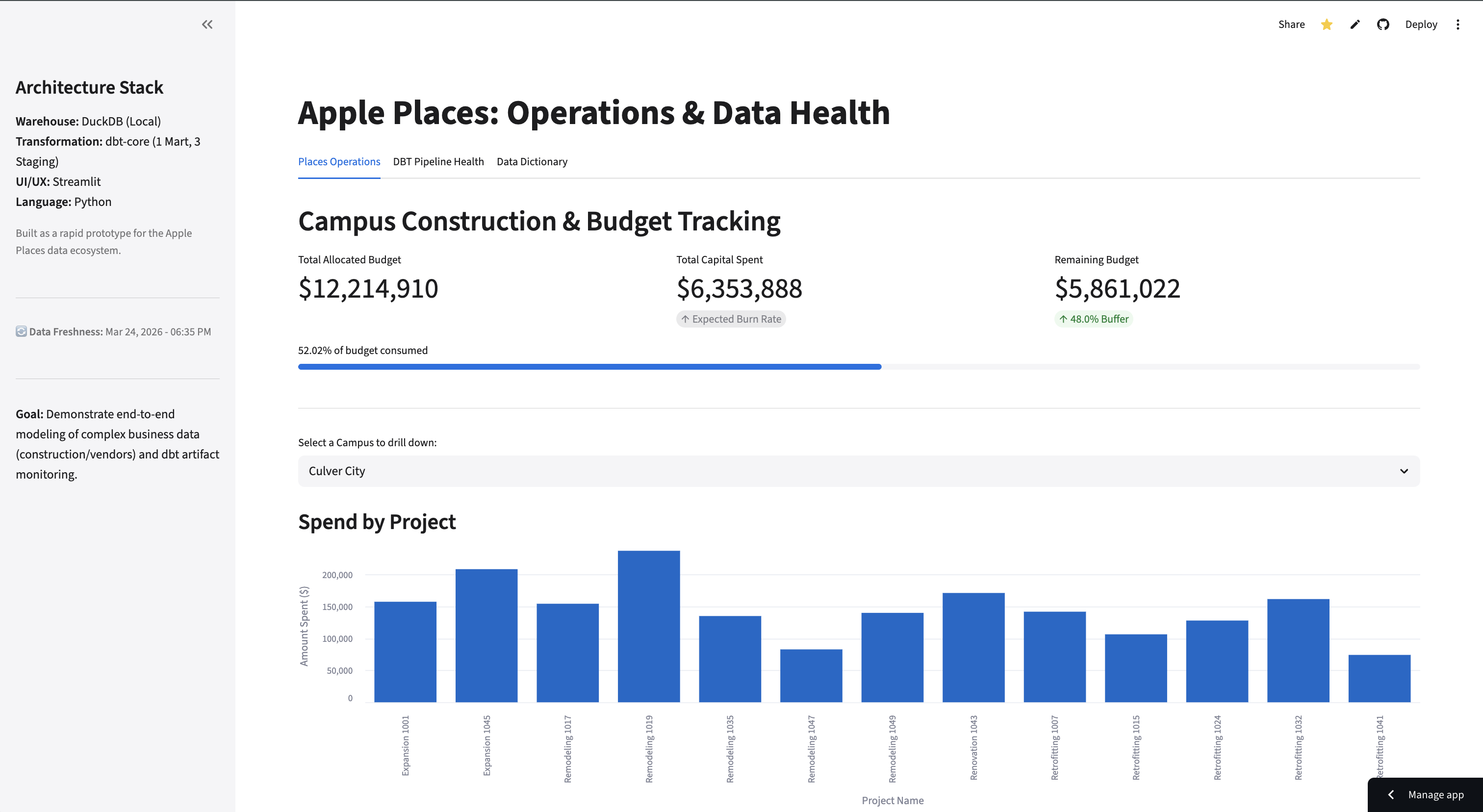
PlacesOps
BI Dashboard & Modern Data Stack Prototype
A BI dashboard prototype built on DuckDB, dbt-core, and Streamlit. Two tabs for two audiences: a capital expenditure view for business stakeholders, and a pipeline health monitor for data engineers — both powered by the same fact table.

App Store Ecosystem Analytics
Interactive Data Storytelling with D3.js
500MB of raw Kaggle data, pre-aggregated down to 50KB via Python, rendered as a smooth animated bar chart race in D3.js. 13 years of App Store genre competition in one visualization. Published on Medium.

Uber NYC Dashboard
Geospatial Analytics Dashboard
Streamlit dashboard exploring Uber pickup and dropoff patterns across New York City. Neighborhood-level breakdowns, time filters, and statistical summaries — built to make the spatial patterns in the data easy to read.
ChatPilot
Multi-Provider AI Chat Application
AI chat application with support for multiple LLM providers (Gemini, OpenAI) via a Streamlit interface. Actively developed — model switching and prompt memory are on the roadmap.
Toolkit
My Toolkit
Tools I reach for — and know well enough to have opinions about.
Data Engineering & Orchestration
Cloud & Data Platforms
Databases & Storage
Visualization & Analytics
Infrastructure & DevOps
Writing
Technical Writing
I write about data engineering patterns, visualization architecture, and lessons from building real systems.
Designing a Scalable Learner Data Pipeline: A Medallion Architecture Approach
A deep-dive into diagnosing four critical anti-patterns in a Matillion + Snowflake ETL design — memory exhaustion, brittle truncate-and-load, slow row-by-row inserts, and hardcoded credentials — and redesigning the pipeline into a robust, idempotent ELT architecture using S3 staging, high-water mark incremental loads, and MERGE-based upserts.
The "Genre Wars": How I Visualized 13 Years of App Store History (Without Crashing Your Browser)
A Data Engineer's guide to turning 500MB of raw logs into a silky-smooth 50KB data story using Python and D3.js. Covers pre-aggregation strategy, D3.js animation architecture, and performance optimization.
Exploring the Relationship Between PPG Data and Heart Rate Variability
An investigation into PPG-based HRV tracking for stress and recovery monitoring. Covers signal processing, data pipeline design for biosensor streams, and insights from real wearable data.